
Mes activités de recherche se situent principalement dans le domaine de la modélisation, l'analyse, la transformation et la synthèse du son musical. Le son est alors un mélange d'entités sonores résultant d'une structuration musicale (organisation temporelle de ces entités). Par définition, chaque entité sonore est perçue individuellement par notre système auditif, et peut correspondre par exemple à une note d'un instrument de musique, ou bien à un phonème, un bruit, etc.
Je m'intéresse aux modèles spectraux, et plus particulièrement aux modèles sinusoïdaux, dérivés des travaux d'Helmholtz et explorés par des pionniers de l'informatique musicale comme Jean-Claude Risset et Max Mathews, suivis plus tard par Robert McAulay et Thomas Quatieri dans le domaine de la parole et par Julius Smith et Xavier Serra dans le domaine de la musique. Ces modèles nécessitent des compétences pluridisciplinaires. Ils reposent sur des bases mathématiques et physiques solides, sont proches de la perception humaine, sont bien adaptés au discours musical, et génèrent un grand nombre de problèmes de nature informatique très intéressants. La structure de base de ces modèles est le partiel, oscillateur quasi sinusoïdal dont les paramètres (fréquence et amplitude) évoluent lentement dans le temps. Nous avons proposé (avec Myriam Desainte-Catherine) le modèle de Synthèse Additive Structurée (SAS) qui contraint ces paramètres pour permettre de modifier indépendamment des grandeurs musicales telles que la hauteur, l'intensité ou la durée, tout en constituant une base solide pour l'étude scientifique du timbre des sons quasi harmoniques. Modéliser les variations de paramètres spectraux également sous forme spectrale nous a récemment permis (avec Martin Raspaud) d'aboutir à des modèles spectraux hiérarchiques, autorisant encore plus de souplesse dans le contrôle du son. La plupart des modèles sonores sont actuellement des modèles hybrides, où la composante bruitée (stochastique) est séparée de la composante sinusoïdale (déterministe). Nous souhaitons maintenant définir un modèle spectral unifié, plus souple, où parties déterministes et stochastiques seraient indissociables.
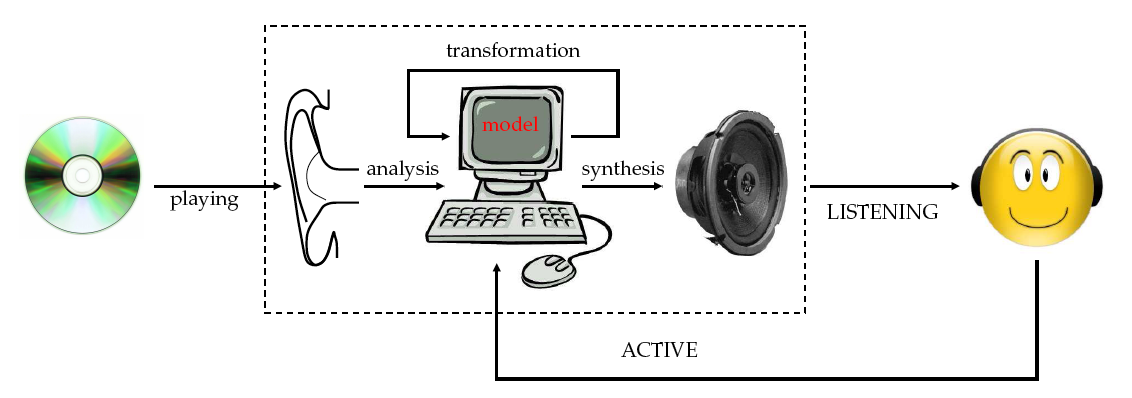
En plus du modèle lui-même, il faut également pouvoir disposer d'une méthode d'analyse précise pour obtenir les paramètres du modèle à partir de sons existants, ainsi qu'une méthode de synthèse rapide pour générer un son numérique à partir de sa modélisation, si possible en temps réel.
Traditionnellement, l'analyse se fait en deux temps: le signal est observé à court terme sur une petite fenêtre temporelle, puis ces observations sont exploitées à plus long terme pour reconstruire les évolutions des paramètres.
Dans un premier temps, il s'agit d'estimer les paramètres instantanés (fréquence et amplitude) des partiels via des méthodes à la fois précises et efficaces. Parmi les méthodes les plus efficaces, on trouve celles basées sur la transformée de Fourier rapide. Mais il faut alors trouver des méthodes pour améliorer la précision. Bien que de nombreuses méthodes aient déjà été proposées précédemment, il s'avère que bien peu sont suffisamment précises. Parmi les plus prometteuses, citons celles exploitant les relations de phase au sein des spectres à court terme obtenus par la transformée de Fourier. Le vocodeur de phase estime de cette manière la fréquence instantanée. La réallocation spectrale est une autre méthode proposée pour améliorer la précision de l'estimation. Nous avons proposé une nouvelle méthode d'analyse basée sur les dérivées du signal sonore. Récemment, grâce à cette méthode, nous avons montré l'équivalence théorique de méthodes d'analyse spectrale parmi les plus utilisées en informatique musicale. Ces méthodes d'analyse spectrale sont en cours de généralisation au cas non stationnaire où les paramètres peuvent varier à l'intérieur même de la fenêtre d'analyse. La généralisation de notre méthode basée sur les dérivées a été étendue récemment en collaboration avec Philippe Depalle (McGill University, Montréal). Cette méthode s'avère être la plus précise dans la plupart des cas. Notons également que les modèles sinusoïdaux non stationnaires, qui reposent sur des sinusoïdes amorties, ont des applications dans de nombreux domaines comme la sismologie ou la reconstruction des images IRM (Imagerie à Résonance Magnétique).
Le point faible des méthodes d'analyse existantes est le suivi des trajectoires des partiels (en fréquence et en amplitude) dans le temps. Notre contribution (avec Mathieu Lagrange et Martin Raspaud) a été de considérer les trajectoires des partiels comme des signaux déterministes et inaudibles. Premièrement, nous avons montré l'utilité de la prédiction linéaire pour effectuer le suivi des partiels. Cette prédiction est si performante qu'elle permet la restauration des sons, qui consiste à retrouver de l'information manquante dans la structure d'un son altéré. Notons que ces techniques sont également employées en mathématiques financières, notamment pour la prédiction du cours des devises. Secondement, la limitation du contenu fréquentiel des trajectoires améliore encore le suivi. L'évaluation des méthodes de suivi est un point essentiel, mais difficile et toujours ouvert.
Les modèles spectraux nécessitent le calcul d'un grand nombre d'oscillateurs sinusoïdaux. Le problème est alors de trouver un algorithme très efficace pour générer la séquence des échantillons de chaque oscillateur avec le moins d'instructions possible. Nous avons développé une méthode de synthèse sonore de complexité quasi optimale, qui repose sur un algorithme optimisé de génération incrémentale de la fonction sinus. Afin d'accélérer encore le processus de synthèse, nous avons étudié (DEA de Mathieu Lagrange) avec succès la possibilité de réduction à la volée du nombre de partiels à synthétiser en tirant parti de phénomènes psychoacoustiques comme le masquage et de structures de données efficaces comme les skip-lists. Cette technique a été utilisée dans le cadre de l'équipe-projet INRIA REVES (travaux de Nicolas Tsingos). Nous disposons de la technique de synthèse linéaire la plus rapide à ce jour. Le DEA de Matthias Robine a montré le manque de souplesse des techniques mathématiques non linéaires qui, bien qu'extrêmement efficaces, s'avèrent inutilisables. Cependant, nous avons proposé avec Robert Strandh (thèse de Matthias Robine) une technique de synthèse rapide originale basée sur un générateur polynomial couplé à une file de priorité. Nous nous sommes également intéressés à l'augmentation de la qualité de la resynthèse. Nous avons étudié (en collaboration avec le LORIA (Nancy), l'Institut de la Communication Parlée (Grenoble) et l'IRCAM (Paris)) divers modèles de phase polynomiaux pour les oscillateurs.
À partir d'un signal sonore, par exemple le son fixé sur un support comme le Compact Disc (CD) audio, je m'efforce d'analyser les différentes entités sonores perçues à l'intérieur de ce son musical afin de pouvoir les transformer individuellement. Si cette analyse et ces transformations se font en temps réel, il est possible de proposer à l'auditeur une expérience d'écoute active : modifier la musique pendant son écoute, par exemple en supprimant la voix chantée (effet karaoké), en modifiant les volumes des différents instruments (par exemple en atténuant la batterie), voire leurs positions (par exemple en déplaçant une guitare de la gauche à la droite). Si ces pratiques sont habituelles pour les compositeurs de musique électro-acoustique avec qui nous collaborons comme ceux du SCRIME, elles sont révolutionnaires pour le grand public, habitué à une écoute plus passive.
La séparation des entités (ou sources) sonores est un défi scientifique majeur. En effet, nous percevons le mélange musical avec nos oreilles, au nombre de 2 (d'où les 2 canaux sur les CD audio), or le nombre d'entités sonores présentes simultanément (polyphonie) dans un son musical est en général bien supérieur à 2. Nous sommes dans un cas mathématiquement "dégénéré", avec moins d'équations que d'inconnues, c'est-à-dire moins de capteurs que de sources. Or le cerveau donne pourtant une solution. En s'inspirant des mécanismes de la perception, nous effectuons une décomposition fréquentielle (spectrale) des signaux et considérons que pour chaque signal il n'y a qu'une entité présente en chaque point (atome) du plan temps / fréquence (hypothèse d'orthogonalité des spectres à court terme). Ensuite, il s'agit de regrouper les atomes spectraux en entités sonores, par exemple sur des critères perceptifs en tirant parti de lois d'acoustique et de psychoacoustique (travaux d'Albert Bregman) : structures spectrales remarquables (sources harmoniques : DEA de Grégory Cartier, thèse de Mathieu Lagrange), simultanéité et cohérence temporelles (mêmes instants d'apparition, évolutions corrélées dans le temps : thèse de Mathieu Lagrange), coïncidence spatiale (mêmes angles d'arrivée : thèse de Joan Mouba), etc. Afin d'aider cette analyse traditionnelle de type CASA (Computational Auditory Scene Analysis), nous envisageons (en collaboration avec Laurent Girin et Cléo Baras, Grenoble) une approche originale dite "informée" consistant à tirer parti d'informations supplémentaires rajoutées de manière inaudible à l'intérieur des sons (tatouage audio-numérique). Cela a donné lieu au projet ANR DReaM que je coordonne nationalement.
Une fois les entités sonores identifiées, il est possible de les contrôler tout en respectant l'oeuvre musicale, par exemple en changeant leurs positions dans l'espace (spatialisation sonore ou "son 3D"), comme indiqué dans la thèse de Joan Mouba sur la manipulation spatiale des sons spectraux. Nous avons proposé une méthode de localisation / spatialisation binaurale (écoute au casque) efficace reposant sur les indices binauraux ILD (Interaural Level Difference) et ITD (Interaural Time Difference), et le modèle simplifié pour les HRTF (Head-Related Transfer Functions) qui en découle. Puis nous avons étendu cette méthode à la multidiffusion (écoute au centre d'un dispositif de haut-parleurs) pour la musique électroacoustique, par une technique qui n'est pas sans rappeler l'approche transaurale. Le tout a été implanté dans le logiciel RetroSpat, un spatialisateur rétroactif, qui a comme originalité de pouvoir ajuster ses coefficients spectraux de spatialisation en fonction du retour binaural d'un mannequin de prise de son (de type KEMAR), afin d'augmenter la qualité de l'immersion 3D. Ce dispositif a été utilisé à Bordeaux en septembre lors de la Nuit des Chercheurs (démonstration publique devant environ 300 personnes). Cette approche permet de s'adapter à tout type de système de diffusion et a des applications en réalité virtuelle / augmentée.